
Data and AI
Data & AI

Let’s consider the early days of a top-tier fraud detection system for banking. In its first week, every flagged transaction requires a human analyst to click "approve" or "deny.” The AI is powerful, but it’s essentially an untrusted intern that isn't allowed to sign checks without passing through a human gate. It needs to “learn.”
In a few months, that same system recognizes the patterns of possible theft versus legitimate travel. It now processes nearly every transaction instantly, only pausing to alert a human when a truly bizarre anomaly occurs. The human analyst has upgraded from doing the work to supervising the work.
This evolution from human-in-the-loop (HITL) to human-on-the-loop (HOTL) is the defining journey of enterprise AI. Understanding this nuance is about more than plain semantics; it’s about how you scale without losing the distinct characteristic of an organization or the safety of human judgment.
Before we can map out this evolution, we have to define these structures and when they’re each useful.
In human-IN-the-loop architecture, the human is an inextricable link to the pipeline and vital for the system to complete a task. This is useful when the AI model is new to a dataset’s complexity or when the cost of error is sensitive. Conversely, human-ON-the-loop AI systems push the human to hold a more supervisory role: the AI is autonomous as a default, and the human serves as a safety net to monitor and intervene when essential. While HITL is about securing task accuracy during training, HOTL is focused on efficiency at scale in a mature production environment.
Integrating human intelligence into AI isn't a sign of weakness; it is a badge of adaptability and sophisticated engineering. In a high-stakes enterprise environment, the goal isn't rote intelligence; without integrity, no amount of automation can build credibility. HITL systems weaving in human expertise brings several strategic advantages:
Better Quality and Intuitive Context: AI is exceptional at identifying patterns, yet it lacks intuition and context. Humans provide the "ground truth" that models need to reach near-flawless accuracy, especially in fields like legal discovery or medical informatics, where a single nuance can be decisive.
Navigating the Unexpected: AI models are fundamentally historical; they can only draw upon what has already occurred. Humans excel at handling edge cases that fall outside training data. These rare scenarios are where systems are most likely to hallucinate.
Compliance and Bias Mitigation: Automated systems can inadvertently amplify biases found in raw data, in any direction. Human oversight acts as a necessary filter for regulatory alignment and ethical guardrails, protecting the organization from legal and reputational risks associated with algorithmic bias.
The Virtuous Feedback Loop: Humans are contributing to an AI model’s active learning process every time they correct or validate its output. This guidance ensures the system matures quicker, becomes more resilient, and gets smarter with every iteration, demanding less intervention over time.
Architectural Trust: Accountability is not a machine trait, but a distinctly human one. Whether with customers, board members, or regulators, stakeholder trust is crucial, and hinges on the assurance that a human expert is the ultimate authority of the system’s performance, and not code vulnerable to the whims of the algorithms.
Across industries, businesses are strategizing human-in-the-loop systems to not just train or "fix" AI, but to fast-track its path to autonomy. Here is how:
Model Training and RLHF: To build a reliable Large Language Model (LLM), raw data isn't enough; Reinforcement Learning from Human Feedback (RLHF) is a vital feedback loop. This is where human experts rank, rate, and refine AI responses to improve their tone, safety, and factual accuracy. This is why companies like Apex Data Sciences can handle these data operations at scale, providing the high-fidelity human feedback necessary for a model to be safely deployed and grow to production.
Content and Data Transformation: Converting legacy archives or unstructured datasets into modern digital formats often involves schemas too complex for basic automation. For example, scalable AI service companies like Apex CoVantage can utilize HITL workflows to ensure data is clean before it ever feeds into an automated pipeline, so process layers such as metadata extraction and structural tagging remain consistent.
Compliance and Regulatory Oversight: In fintech and legal sectors, AI can do the heavy lifting of flagging money laundering or identifying relevant case law. However, the final judgment call relies on a human officer to sign off, fulfilling stricter "know your customer" (KYC) regulations and legal standards that a machine cannot legally satisfy.
Digital Accessibility: AI can help generate alt-text and captions, but creating a truly inclusive web experience for users with visual or auditory impairments depends on verifying that these descriptions are more than just technically present. Human reviewers are essential here to verify these accessible features are contextually relevant and helpful.

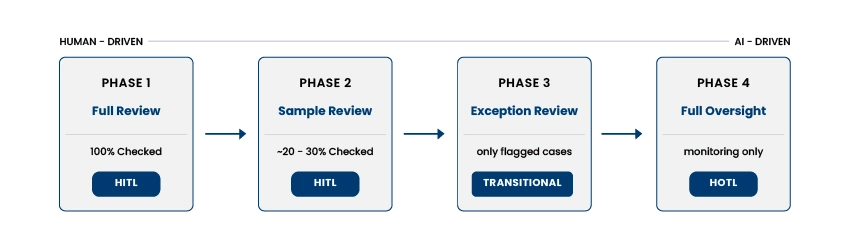
The shift from HITL to HOTL is not a binary switch we can flip, but a graduated handoff, tallying the model's evolving evidence of competence to the changing stakes of being wrong. In practice, most enterprise deployments move through four phases.
The model is new, the data unfamiliar. Every output must pass through human hands. This pipeline is slow and expensive, but two things are happening that matter more than efficiency: the human team is carefully mapping points of failure, and every correction is enriching the training feedback loop. The human role is at times manual and crucially indispensable.
Once accuracy stabilizes on routine cases, reviewers can shift to sampling. Low-risk outputs are spot-checked at perhaps a 20–30% threshold; high-risk categories still receive 100% scrutiny. This is where we notice the first efficiency gain, and is the first real test of the model's reliability. The human role is starting to move up.
The model begins reporting its own confidence. High-confidence outputs are now routine and flow through automatically; only in flagged or ambiguous cases are humans brought in. The human role has evolved from gatekeeper to specialist.
The model now runs most workflows end-to-end. Humans watch dashboards for bias drift, anomalies, and escalations, no longer touching individual decisions in the normal course of work. They don’t need to; they govern the system.
A simple way to visualize this arc:
The model’s confidence is correlated to the consequence of an error; the AI model’s entire evolution timeline hinges on these two variables. A model with strong accuracy on low-stakes slogan generation may graduate to HOTL in weeks; the same model recommending clinical dosage adjustments may never leave HITL, nor should it.
The handoff to HOTL is earned, not assumed. This is where rigorous human data services become core structural foundations rather than ornamental pillars. Without that foundation, no model accumulates enough evidence to graduate. Clean labeled data, well-curated edge cases, and a continuous stream of human reviewer feedback are what transform a model from probable usefulness to demonstrably trustworthy.
Two questions decide when AI can work alone:
Plotted against each other, they produce four clear modes:
The rule is simple enough: AI works alone only when confidence is high and risk is low. Everywhere else in the matrix, humans stay involved on at least some level.
A few tips that help:
A working HITL-to-HOTL transition shows up in three metrics moving the right way:
Note: If reviews are dropping but so is accuracy, the handoff is moving too fast. If accuracy holds but reviewers are still checking routine cases, the team hasn't adjusted to the new mode; usually this is a threshold or escalation issue.
The evolution from human-in-the-loop to human-on-the-loop is how AI systems mature. It begins with humans validating every single output, narrows to sampling, narrows again to handling exceptions, and finally settles into supervision and oversight. What carries a system from start to finish isn't the AI model alone, but the strategic and disciplined accumulation of human judgment that earns it its independence. Done well, enterprises make real what they set out to build: scale without giving up peace of mind.



